이제야 정리하는 트랜잭션! Java Spring에서 트랜잭션을 어떻게 사용하는지 정리해보았다.
글을 쓰면서 @Transaction의 사용 위치, 격리성 문제 등 더 알아가야 할 내용이 많이 보여 다른 포스팅으로 돌아와야할 것 같다. 사실 테스트 코드에 트랜잭션을 적용해보고싶어서 방법을 찾던 와중에 이에 대한 많은 고민과 의견들이 있길래 흥미롭게 이것 저것 찾아보고 정리해보려고 했는데, 이해가 잘 가지 않아 힘들었다. 트랜잭션 자체에 대해서 아무것도 모르니 일단 기초부터 공부해보자!!
트랜잭션
애플리케이션에서 어떤 기능이 동작할 때 여러 개의 쿼리가 실행될 수 있다. 이 경우 모든 쿼리가 다 에러 없이 실행되어야 그 기능이 정상동작했다고 말할 수 있다. 트랜잭션은 트랜잭션 범위에서 실행된 모든 쿼리가 다 에러 없이 실행되었는지 확인하고 에러가 없으면 DB에 commit, 아니면 rollback한다.
예를 들어 사용 가능한 이메일인지 확인하는 기능이 있다고 하자. 확인하고싶은 이메일 주소로 링크를 하나 보내면 그 링크를 클릭해서 사용 가능하다는 인증을 완료한다.
이 기능을 수행하기 위해서는 두 개의 쿼리가 수행되어야 한다.
String query1 = "update MEMBER set EMAIL=?";
String query2 = "insert into EMAIL_AUTH values (?, 'True')";인증 완료되면 멤버의 이메일을 수정하는 쿼리
인증 상태를 True로 변경하는 쿼리
그런데 첫 번째 쿼리는 정상적으로 실행이 됐는데 두 번째 쿼리는 실패했다고 해보자. 예를 들어 코드를 잘못 작성해서 테이블 이름을 틀렸다든가, 중복된 값이 있어서 insert하지 못했다.
그러면 이메일 수정은 잘 됐는데 EMAIL_AUTH는 여전히 FALSE로 남아있게 될 것이다. 이렇게 되면 데이터 무결성이 깨지고 데이터를 신뢰할 수 없게 된다.
따라서 두 번째 쿼리가 실패하면 첫 번쨰 쿼리도 DB에 반영하지 않게 해야 데이터가 일관되고 정확한 상태를 유지할 수 있다.
이렇게 두 개 이상의 쿼리를 한 작업으로 수행해야 할 경우 트랜잭션을 사용해야 한다. 트랜잭션은 여러 쿼리를 논리적으로 한 작업으로 묶는다.
그 중 하나라도 실패하면 전체 쿼리를 실패로 간주하고 모든 쿼리 실행 결과를 취소한 후 DB를 기존 상태로 되돌린다. (rollback)
모든 쿼리가 성공하면 쿼리 실행 결과를 DB에 반영한다. (commit)
트랜잭션을 시작하면 커밋하거나 롤백할 때까지 실행한 쿼리들이 하나의 작업 단위가 되는 셈이다.
프로그래밍 방식을 이용한 트랜잭션 처리
이제 트랜잭션을 어떻게 사용하는지 알아보자. 스프링은 commit, rollback 등의 트랜잭션 처리를 자동으로 해주는 @Transaction 어노테이션을 제공한다. 어노테이션을 사용하지 않으면 아래와 같이 코드로 직접 트랜잭션을 관리해야 한다. try-catch문으로 일일이 쿼리의 예외를 처리해줘야 하고 커밋과 롤백을 알맞은 곳에 삽입해야 한다. 대충 봐도 비효율적인 방법이다. 개발자가 커밋이나 롤백을 누락하기 쉽고, 똑같은 구조가 매번 반복되기 때문에 중복 코드가 많아지기 때문이다.
또한 사용하는 데이터 접근 기술에 따라서 트랜잭션 처리하는 방법이 다르다. 데이터 접근 기술로 JDBC를 쓰다가 JPA로 바꾸면 트랜잭션 코드도 다 변경해야 한다. 아래 코드는 JDBC는 Connection객체를, JPA는 EntityTransaction을 사용해서 트랜잭션을 처리하는 모습이다.
//JDBC의 트랜잭션 처리
public void accountTransfer(String id) throws SQLException{
Connection conn = DriverManager.getConnection("jdbcUrl", "user", "pw");
//Connection conn = dataSource.getConnection();
try {
conn.setAutoCommit(false); //트랜잭션 시작
//... 쿼리 실행
conn.commit(); //성공 시 커밋
}catch (SQLException ex){
if(conn != null)
try{ conn.rollback(); } catch (SQLException e){} //실패 시 롤백
} finally {
if(conn != null)
try{ conn.close(); } catch (SQLException e){} //실패 시 롤백
}
}//JPA의 트랜잭션 처리
@RequiredArgsConstructor
public class tmpTEST {
private final EntityManager em;
private final EntityTransaction ts;
public void accountTransfer(String id){
try{
ts.begin(); //트랜잭션 시작
// ...쿼리 실행
ts.commit(); //성공하면 커밋
}catch(Exception e){
ts.rollback(); //실패하면 롤백
}finally{
em.close();
}
}
}선언적 방법(@Transaction)을 이용한 트랜잭션 처리
스프링이 제공하는 @Transaction 기능을 사용하면 개발자가 직접 트랜잭션을 시작하고 커밋, 롤백하지 않아도 된다. 프록시 객체가 트랜잭션을 시작하고, 실제 객체를 호출하고, 쿼리 실행이 모두 성공하면 트랜잭션을 종료한다. 따라서 코드 중복이 없어지고, 트랜잭션을 처리하는 부분이 모두 프록시에서 실행되기 때문에 Service계층은 순수한 비즈니스 로직 코드만 유지할 수 있다. 또한 데이터 접근 기술의 종류가 바뀌어도 코드 수정 없이 트랜잭션을 쓸 수 있다.
(프록시에 대해서는 나중에 포스팅할 예정. 예외처리와 커밋 롤백을 자동화할 수 있다는 정도만 이해하고 일단 어노테이션 사용법 먼저 알아보자)
- 트랜잭션 범위를 지정하고싶은 곳에 @Transaction 붙이기
사용 방법은 원하는 곳에 어노테이션을 붙이기만 하면 된다. 이제 이 클래스 내에서 실행되는 모든 쿼리들은 한 트랜잭션 안에 묶인다. 이 쿼리 중 하나라도 실패하면 rollback되고, 모두 성공하면 commit 후 DB에 반영된다.
@Service
@Transactional //트랜잭션 범위 지정
public class UserService {
...
}- 데이터 접근 기술에 맞게 TransactionManager 설정해주기
스프링의 @Transaction은 사용 중인 데이터 접근 기술에 상관 없이 동일한 방식으로 트랜잭션을 처리할 수 있도록 PlatformTransactionManager라는 인터페이스를 사용한다.
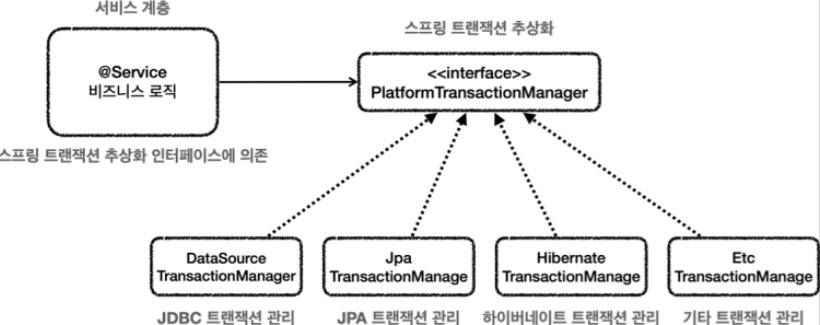
데이터 접근 기술이 바뀌면 이 인터페이스의 구현체를 갈아끼우기만 하면 된다. 만약 JDBC를 쓰고 있다면 구현체는 DataSourceTransactionManager가 될 것이고, JPA로 바꾸면 구현체는 TransactionManager가 될 것이다. 따라서 구현체를 설정해줘야 한다.
구현체 설정 방법은 Spring Legacy에서는 개발자가 직접 설정파일(Config파일)을 만들어줘야 하고, Spring Boot를 사용한다면 자동 구성에 의해 알아서 처리된다.
Spring Legacy
Spring Legacy에서는 개발자가 @Configuration 파일에 구현체의 Bean을 직접 등록하고 @EnableTransactionManagement로 트랜잭션을 활성화해야 한다. (설정 파일에 @EnableTransactionManagement을 붙여야 스프링이 @Transactional이 붙은 곳을 인식하고 트랜잭션 처리할 수 있게 됨)
@Configuration //설정 파일
@EnableTransacctionManagement //트랜잭션이 실행되도록 활성화
public class AppCtx{
//인터페이스의 구현체를 직접 Bean으로 등록
@Bean
public PlatformTransactionManager transactionManager(){
DataSourceTransactionManager tm = new DataSourceTransactionManager(); //JDBC 사용
tm.setDataSource(dataSource());
return tm;
}
}Spring Boot
Spring Boot를 쓰면 자동 구성(Auto-configuration)을 통해 데이터 접근 기술을 인식하고 해당 구현체를 Bean으로 등록해준다. 예를 들어 Bean에 jakarta.persistence.EntityManager가 등록되어있으면 JPA를 쓰고있다고 인식하고 인터페이스의 구현체로 TransactionManager의 Bean이 등록된다. (자동 구성 포스팅 내용 참고)
@Transactional에 의해 트랜잭션이 처리되는 과정
트랜잭션을 적용하고싶은 곳에 @Transactional을 붙이고 TransactionManager을 Bean으로 등록하는 설정을 완료했다. 이제 @Transaction이 적용된 메소드를 실행시켰을 때 어떻게 처리되는지 알아보자.
- 프록시가 함수 호출, commit, rollback 처리
@Service
public class ChangePasswordService {
@Transactional //(1) 스프링이 프록시 객체 생성
public void changePassword(String email, String oldPwd, String newPwd) {
...
}
}public class Main {
public static void main(String[] args){
@Autowired
private ChangePasswordService service; //(2) 프록시 객체가 할당됨
service.changePassword("xxx@xxx.xom", "1234", "5678"); //(3) 프록시 객체가 (트랜잭션이 적용된) 함수 호출
}
}애플리케이션이 실행되면 스프링은 설정 파일을 읽어서 애플리케이션 컨텍스트를 초기화할 것이다. 이때 @Transaction이 적용된 Bean 객체를 발견하면 프록시 객체를 생성하고, 트랜잭션 처리 시 프록시 객체를 이용한다.
1. ChangePasswordService에 @Transactional이 적용되어있으므로 스프링이 프록시 객체 생성
2. ChangePasswordService의 객체로 실제 객체가 아니라 프록시 객체가 할당됨
(여기서부터 프록시 객체가 하는 일)
3. main()에서 @Transactional이 적용된 changePassword() 호출
4. PlatformTransactionManager의 getTransection()을 호출 -> 트랜잭션이 시작됨
5. 실제 service 객체의 changePassword() 호출
6-1. (성공적으로 실행되면) PlatformTransactionManager의 commit()을 호출 -> 커밋
7-1. 리턴
6-2. (RuntimeException이 발생하면) PlatformTransactionManager의 rollback()을 호출 -> 롤백
7-2. main()으로 예외 던짐
*성공적으로 실행되었다는 것은 모든 메서드가 Error나 RuntimeException을 던지지 않고 정상적인 값을 반환했으며, 더 이상 실행할 코드가 없는 상황을 의미*트랜잭션은 Unchecked Exception(Runtime Exception 및 그 하위)이 발생하면 롤백한다. 그러나 Checked Exception의 영향은 받지 않는다. Checked의 경우 개발자가 명시적으로 예외를 던져서 롤백시킬 수 있다.
- rollback 처리 대상 설정
실제 객체의 메서드를 실행하는 과정에서 RuntimeException 이 발생하면 트랜잭션이 롤백되지만, 그 외의 익셉션이 발생할 경우 롤백하지 않는다. 따라서 RuntimeException을 상속받지 않는 예외가 발생했을 때도 롤백 처리 하고싶은 경우 아래와 같이 설정을 주면 된다.
@Transactional(rollbackFor=SQLException.class)
@Transactional(rollbackFor={SQLException.class, IOException.class}) //여러 개일 경우@Transactional의 주요 속성
- Value
value로 아무 값도 지정해주지 않으면 설정 파일에서 PlatformTransactionManager타입으로 등록된 Bean을 트랜잭션 관리자로 지정한다. 아래의 경우 DataSourceTransactionManager로 지정된다.
@Configuration
@EnableTransacctionManagement
public class AppCtx{
@Bean
public PlatformTransactionManager transactionManager(){
DataSourceTransactionManager tm = new DataSourceTransactionManager();
tm.setDataSource(dataSource());
return tm;
}
}- Propagation
호출되는 메서드 간에 트랜잭션을 어떻게 전파할지 지정할 수 있다. default 값은 REQUIRED이다.
|
타입
|
설명
|
|
REQUIRED
|
메서드를 수행하는 데 트랜잭션이 필요하다는 의미이다.
이미 수행 중인 트랜잭션이 있다면 해당 트랜잭션을 사용하고, 없다면 새로운 트랜잭션을 생성한다. |
|
MANDATORY
|
마찬가지로 메서드를 수행하는 데 트랜잭션이 필요하다는 의미이다.
이미 수행 중인 트랜잭션이 있다면 해당 트랜잭션을 사용하고, 없다면 익셉션이 발생한다. |
|
REQUIRES_NEW
|
항상 새로운 트랜잭션이 필요하다는 의미이다.
이미 수행 중인 트랜잭션이 있다면 일시 중지하고 새로운 트랜잭션을 시작한 후, 새로운 트랜잭션이 종료되면 다시 기존 트랜잭션이 계속된다. |
|
SUPPORTS
|
메서드가 트랜잭션을 필요로 하진 않지만, 이미 수행 중인 트랜잭션이 있다면 트랜잭션을 사용한다는 의미이다.
이미 수행 중인 트랜잭션이 없어도 아무 문제 없이 동작한다. |
|
NOT_SUPPORTED
|
메서드가 트랜잭션을 필요로 하지 않는다는 의미이다.
이미 수행 중인 트랜잭션이 있다면 일시 중지되고 메서드가 다 실행되고 나면 기존 트랜잭션이 계속된다. |
|
NEVER
|
메서드가 트랜잭션을 필요로 하지 않는다.
이미 수행 중인 트랜잭션이 존재하면 익셉션이 발생한다. |
|
NESTED
|
진행 중인 트랜잭션이 존재하면 기존 트랜잭션에 중첩된 트랜잭션에서 메서드를 실행한다. 진행 중인 트랜잭션이 존재하지 않으면 REQUIRED와 동일하게 동작한다. (JDBC 3.0 드라이버 사용 시에만 적용됨)
|
@Service
public class UserService{
@Transactional
public void changeUserName(String id, String name) {
findUser(id);
...
}
@Transactional
public void findUser(String id){
...
}
}예를 들어 위 코드의 경우 changeUserName()이 내부적으로 findUser()을 호출하고 있다. 그런데 두 메서드 모두 트랜잭션이 걸려있다. 따라서 프록시가 changeUserName()을 호출할 때 트랜잭션이 시작하고, findUser()을 호출할 때도 트랜잭션이 시작될 것이다.
만약 propagation을 지정하지 않았으면 기본 값인 REQUIRED로 동작한다. findUser()이 호출될 때 이미 진행 중인 트랜잭션이 있으므로 해당 트랜잭션을 사용한다. 즉 두 메서드가 한 트랜잭션으로 묶여서 실행된다.
- Isolation
@Transactional(isolation=Isolation.DEFAULT)
@Transactional(isolation=Isolation.READ_COMMITTED)동시에 DB에 접근할 때 그 접근을 어떻게 제어할 지 정할 수 있다. 트랜잭션 격리 수준을 가장 엄격한 수준인 SERIALIZABLE로 설정하면 동일 데이터에 100개의 연결이 접근하면 한 번에 한 개씩만 처리되기 때문에 100개의 연결이 줄 서서 기다리고 있는 상황이 된다. 따라서 애플리케이션의 속도를 고려하여 트랜잭션 격리 수준을 지정하는 것이 중요하다. 트랜잭션 격리 수준에 관한 문제는 성능과 연결되어있으므로 나중에 따로 다뤄볼 예정이다.
|
값
|
설명
|
|
DEFAULT
|
기본설정 사용
|
|
READ_UNCOMMITTED
|
다른 트랜잭션이 커밋하지 않은 데이터를 읽을 수 있음
사실상 격리를 하지 않는 수준이다. |
|
READ_COMMITTED
|
다른 트랜잭션이 커밋한 데이터를 읽을 수 있음
트랜잭션 처리가 종료될 때까지 다른 트랜잭션은 해당 데이터에 접근할 수 없다. |
|
REPEATABLE_READ
|
처음 읽어온 데이터, 두 번째로 읽어온 데이터가 동일한 값을 가짐
|
|
SERIALIZABLE
|
동일 데이터에 대해 동시에 두 개 이상의 트랜잭션을 수행할 수 없음
|
트랜잭션 로그 메시지 출력하기
트랜잭션을 사용하면 트랜잭션 실행 상태를 콘솔 창에 로그로 출력해서 확인해야 하는 상황이 생긴다.
Spring Boot의 Logging Framework로는 가장 오래된 Log4j과 Log4j 이후 출시된 Logback이 있다.
- Logback 설치
Spring Boot에는 Logback이 기본적으로 포함되어있어서 별도의 의존성 추가 없이 빠르게 사용할 수 있다. Slf4j는 인터페이스이고, Logback은 Slf4j의 구현체이다. 라이브러리를 살펴보면 이미 Logback과 slf4j이 사용되고 있는 것을 확인할 수 있다.
클래스 레벨에 @Slf4j를 붙여주거나 Logger logger = LoggerFactory.getLogger(...);처럼 LoggerFactory를 직접 생성해서 로그를 남길 수 있다.
- 로그 수준 변경하는 방법
Spring Boot에서 콘솔 로그 수준을 변경하는 방법은 두 가지이다.
1. application.properties : 세부적인 설정 불가
2. 로깅 설정 파일 (.xml) : 세부적인 설정 가능
세부적인 설정이 가능한 2번 방법을 사용해보자.
Spring Boot에는 로깅 설정 파일 네이밍 규칙이 있다. 애플리케이션이 로딩될 때 해당 이름을 가진 로그 설정 파일이 존재하는지 스캔하고, 파일에 정의된 대로 로그를 콘솔에 출력한다. 넷 중 logback-spring.xml으로 설정해야 Spring Boot의 로깅 확장 기능을 쓸 수 있다.
- logback-spring.xml
- logback-spring.groovy
- logback.xml
- logback.groovy
xml 파일을 작성하기 전에 Logback의 구조를 살펴보자.
- Logger : 로그 레벨 수준 결정
- log.info()
- log.error()
- Appender : 로그 메시지가 출력할 대상을 결정. 각 Logger는 하나의 Appender에 연결될 수 있다.
- FileAppender
- ConsoleAppender
- Layout : 로그 메시지를 어떤 형식으로 변환해서 출력해줄지 결정
- PatternLayout
<!-- logback-spring.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<property name="CONSOLE_LOG_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %clr(%5level) %cyan(%logger) - %msg%n"/>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>설정 별로 하나씩 설명 )
//Spring Boot에서 제공하는 Logback 컨버터(ColorConverter)로 색상을 입혀서 출력
<conversionRule conversionWord="clr"
converterClass="org.springframework.boot.logging.logback.ColorConverter"/><property name="CONSOLE_LOG_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %clr(%5level) %cyan(%logger) - %msg%n"/>
//설명
{yyyy-MM-dd HH:mm:ss.SSS} //로그 이벤트가 발생한 날짜, 시간
[%thread] //로그 이벤트를 발생시킨 스레드 이름
%clr(%5level) //clr 변환 키워드를 사용해 로그 레벨 (info, error 등)을 색상 입혀서 출력
%cyan(%logger) //로거 이름을 시안색으로 출력
%msg //로그 메시지 내용 표시
%n" //줄바꿈//앞서 정의했던 pattern을 지정
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
</encoder>
</appender>//appender 이름을 CONSOLE로 지정, logger 레벨을 INFO로 지정
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
최범균 저 '스프링 5 프로그래밍 입문' 외 여러 블로그를 참고하여 작성한 글입니다.
잘못된 정보가 있다면 언제든지 댓글을 달아주세요 ;)
'데이터베이스' 카테고리의 다른 글
| [DB / 테스트] @DataJpaTest (0) | 2024.11.26 |
|---|---|
| [DB / H2] spring.jpa.properties.hibernate.globally_quoted_identifiers=true 설정 (0) | 2024.11.26 |
| [DB / Error] Caused by: org.h2.jdbc.JdbcSQLSyntaxErrorException: Syntax error in SQL statement "\000d\000a (0) | 2024.11.25 |
| [DB] Error / engine[*]=InnoDB"; expected "identifier";] (0) | 2024.11.24 |
| [DB / MySQL] Index의 동작 원리 (0) | 2024.07.11 |